I’m out of school a couple months now, but I’ve had this idea rolling around in my head for a while ever since I saw someone struggle with a nonsense mnemonic.
We’ve got to first figure out the kind of mnemonic we want to generate (for a full list check out https://en.wikipedia.org/wiki/Mnemonic#Types). I’m more excited to generate expression/word mnemonics (Every Good Boy Deserves Fudge for the lines on the staff for the bass clef) over name mnemonics (ROYGBIV for colors of the rainbow) for a number of reasons. Firstly, expression types can inherently preserve order. Secondly, there’s some useful cryptographic applications with them; we can generate a mnemonic passphrase that’s easier to remember than a nonsense string of words.
The two most commonly used approaches for sentence generation are n-grams and markov chains. Simplified, n-grams (commonly bigrams and trigrams) are contiguous sequences of words that commonly occur together, usually collected from text. Markov chains are slightly cooler, and store state probabilities. For example, a two state markov chain would have probabilities that describe when a state changes. This image I pulled off the Wikipedia entry for Markov Chains should do a better job of explaining it.
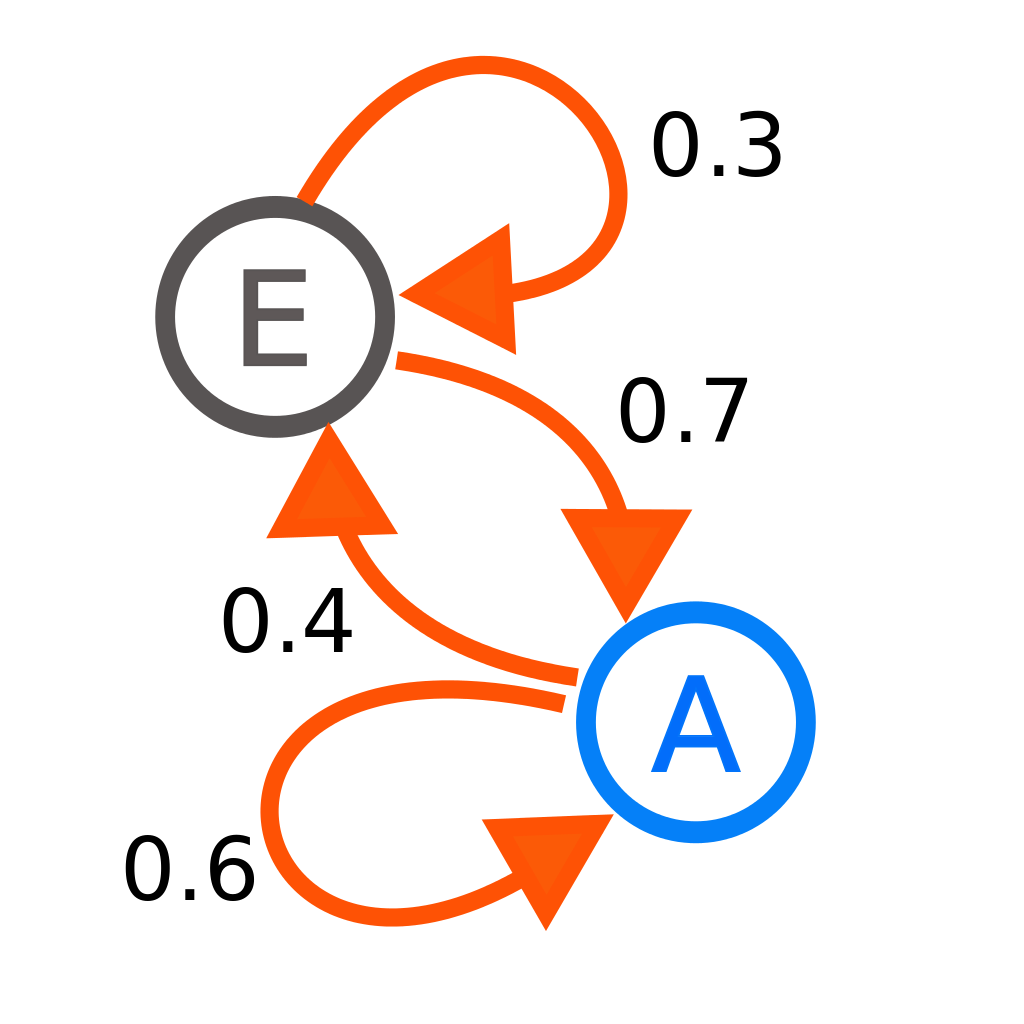
For example, at A, there’s a 40% probability of switching states to E and a 60% probability of staying at A.
I’m going to go with using Markov Chains to generate my mnemonics. The biggest reason I’m not just building and training a ML model is because I want this to be extensible and have a (relatively) lighter footprint. There’s a lot more plug and play with your input data as well if you’re not using a Neural Network.
Writing it
The process was relatively straightforward once I figured it out. I first selected and tagged a piece of text, or corpus. Tagging text in natural language processing (NLP) means processing a sequence of words and attaching a part of speech, or POS tag to each of them (classifying the word as a verb, noun, adjective, interjection, etc etc). The POS tag is what I use to make the Markov Chains really tick.
A dumbed down chain would just pick the most frequently paired word, but by forcing the chain to consider the POS tag, you generate text that is slightly more meaningful. Essentially, the tags store grammatical flow (the same way a Context Free Grammar would), ensuring that the mnemonic you make or the text you generate is not just a sequence of nouns.
Thankfully, NLTK comes with a POS tagger. So after splitting (or tokenizing) our input corpus, I generate dictionaries of (word, tag) pairs and just tags; where each dict entry stores a user-defined number of following words and the number of times they occur after the word in the dict entry. This number is called the Markov Order.
def gen_dicts(tagged):
markov_dict = defaultdict(dict)
tag_dict = defaultdict(dict)
# fill markov dict
tag_length = len(tagged)
for i in range(0, (tag_length - MARKOV_ORDER)):
for j in range(i+1, i+MARKOV_ORDER):
try:
markov_dict[tagged[i]][tagged[j]] += 1
except KeyError:
markov_dict[tagged[i]][tagged[j]] = 1
# fill tag dict
for i in range(0, (tag_length - MARKOV_ORDER)):
for j in range(i+1, i+MARKOV_ORDER):
try:
tag_dict[tagged[i][1]][tagged[j][1]] += 1
except KeyError:
tag_dict[tagged[i][1]][tagged[j][1]] = 1
return markov_dict, tag_dict
A sample markov_dict entry:
markov_dict[1] = {ice: {
cream: 6,
water: 4,
fire: 2 }}
After that, the work is just going through the Markov dictionary, starting at the first letter of the mnemonic. I generate a list of words from the dictionary, and randomly pick one from it; getting the ball rolling.
Finally, it’s just iterating through the dict and then picking the word that has the highest probability of being next in line. If there isn’t a word in the chain that starts with the next letter, then I grab the tag with the highest probability of being next in line and then pick a corresponding word with the tag. The code is up on my github.
Examples
I used Neal Stephenson’s In the Beginning Was the Command Line essay as the input while testing it, because it’s cool and also the only piece of large and freely available text on the internet I could think of. In hindsight it wasn’t a great idea because it’s shorter than it should be for something like this. Having a large dataset is the best way to generate something more meaningful. For this, I collated the first few ebooks from Project Gutenberg’s Top 100: Pride and Prejudice (Jane Austen), Little Women (Louisa May Alcott) and The Adventures of Sherlock Holmes (Arthur Conan Doyle).
So here’s some sample mnemonics I’ve made. The first word is selected randomly, so you’ll usually get a different one each time you run the code.
Colors of the Rainbow
gen_mnemonic('ex.txt', 'r o y g b i v')
'remedy or yield greatly began in visions'
Bass Cleff (Lines and Spaces)
gen_mnemonic('ex.txt', 'g b d f a')
'glittering but darkened four away'
gen_mnemonic('ex.txt', 'a c e g')
'affection clung even girls'
Favorite order of planets for a Mass Effect and KOTOR Playthrough
gen_mnemonic('ex.txt', 'feros therum noveria virmire')
'fair? Two nothing. very'
gen_mnemonic('ex.txt', 'tatooine kashyykk manaan korriban')
'that kiss mother knows'
So the Mass Effect one is a little bit nonsense-y, but I’m gonna blame that on the corpus I’m using.
I gotta say, this took a bit longer than I expected, and not only because I’ve been a lot busier than I thought I’d be this summer. There’s a lot of ideas for this blog I’ve been mulling over, and I’m excited to jump on them once things settle down a bit.