I came across a (super pretty) article about measuring repetitiveness in music lyrics using the Lempel-Ziv algorithm (which exploits an input’s repeated sequences) to observe the degree of compressibility. I thought it would be the exact kind of apolitical fun I like to indulge in if I extended the core idea to analyzing Trump’s interview transcripts and comparing the results to other presidents.
Speeches
I crawled through some of Trump’s interviews on USCB’s American Presidency Project using BeautifulSoup. I chose to use interviews over oral addresses or speeches since they’d be the most natural representation of speech and less likely to have been influenced by a team of writers.
This worked fine, except for the fact that every speech from every president I threw at the code gave me a degree of compression that all hovered around 50.15%. This intuitively makes sense; the level of variability between presidential speeches would not be so high as to account for changes in language. Further, the likelihood of Presidential characteristics having a big enough impact to make a dent in the degree of compressibility is pretty low.
This is also good, since we can have some fun instead using Python’s Natural Language Toolkit (NLTK), which comes with a range of tools that’ll let us develop and apply strong linguistic metrics to analyze the interviews.
Quick aside
First though, I think it’s important to note that any semantic measure in presidential speech isn’t at all indicative of oratory skill or how good of a leader you are. It actually tends to favor your argument and how well it sticks if it’s reiterated a few times or if your diction is simple. Draw whatever conclusions you will from the results, I’m just screwing around with Python and indulging in an interest in computational linguistics.
Lexical Richness/Diversity
OK, Lexical Richness is up first. It’s a fairly easy thing to measure using NLTK. This shows us how much each word is used on average. I use the inverse of Yule’s I characteristic (a statistical measure) to assess the richness. The larger Yule’s I is, the more diversity there is in the text. There was a bit of variability in the scores when I calculated it over 10 interview samples for each president, which is probably accounted for by the length of the input text. I’m also using a pretty small sample size (because the website doesn’t have too many interview transcripts for older presidents).
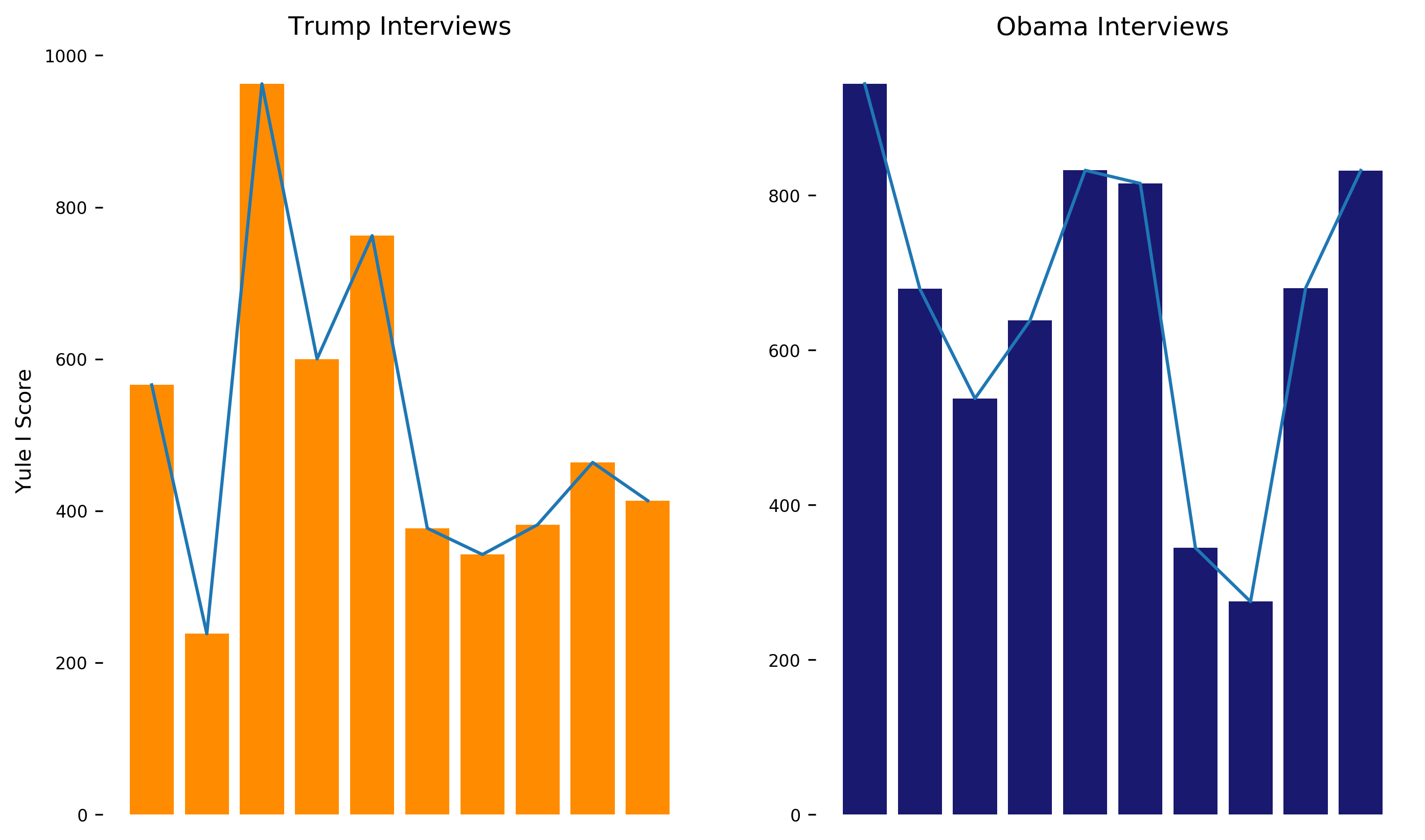
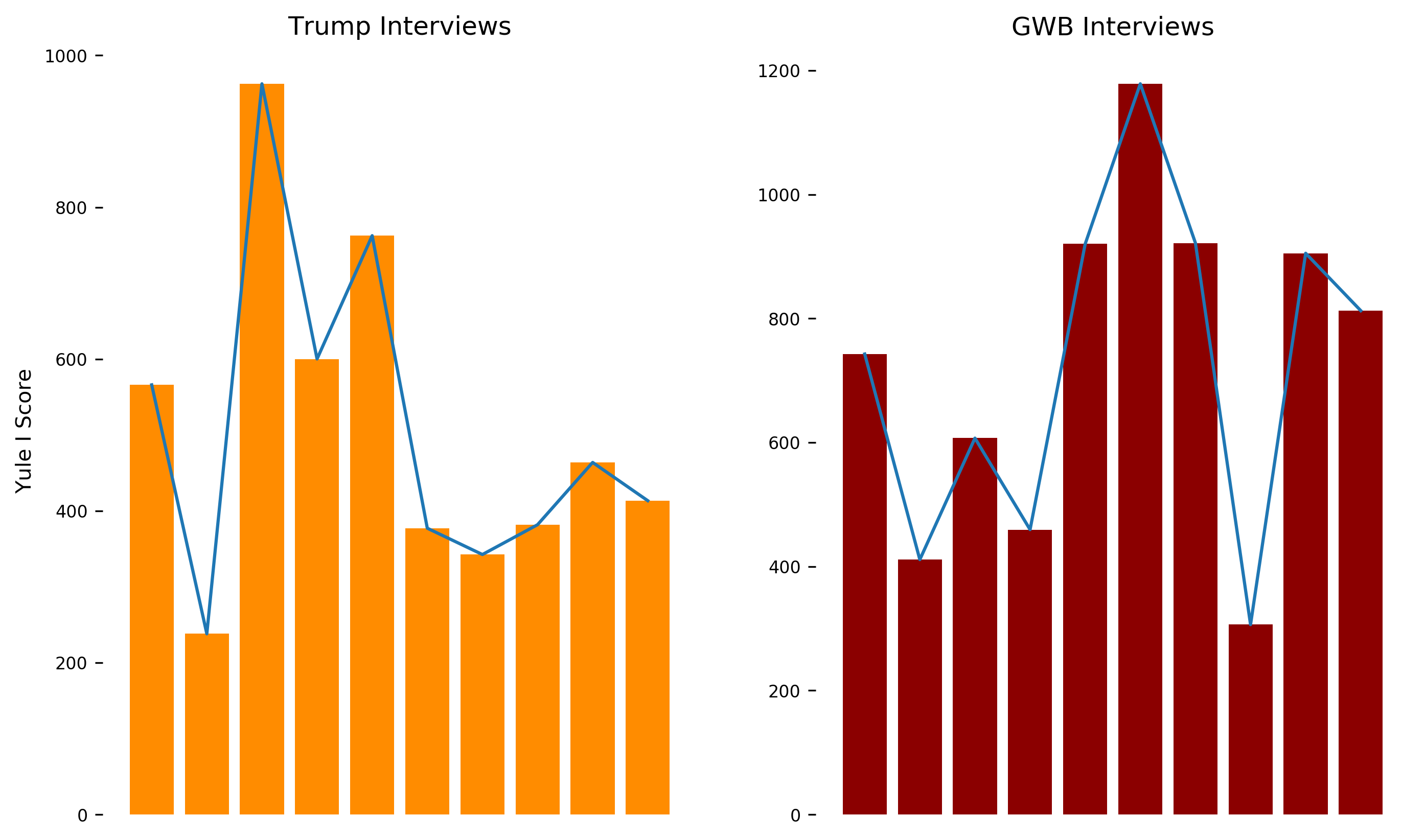
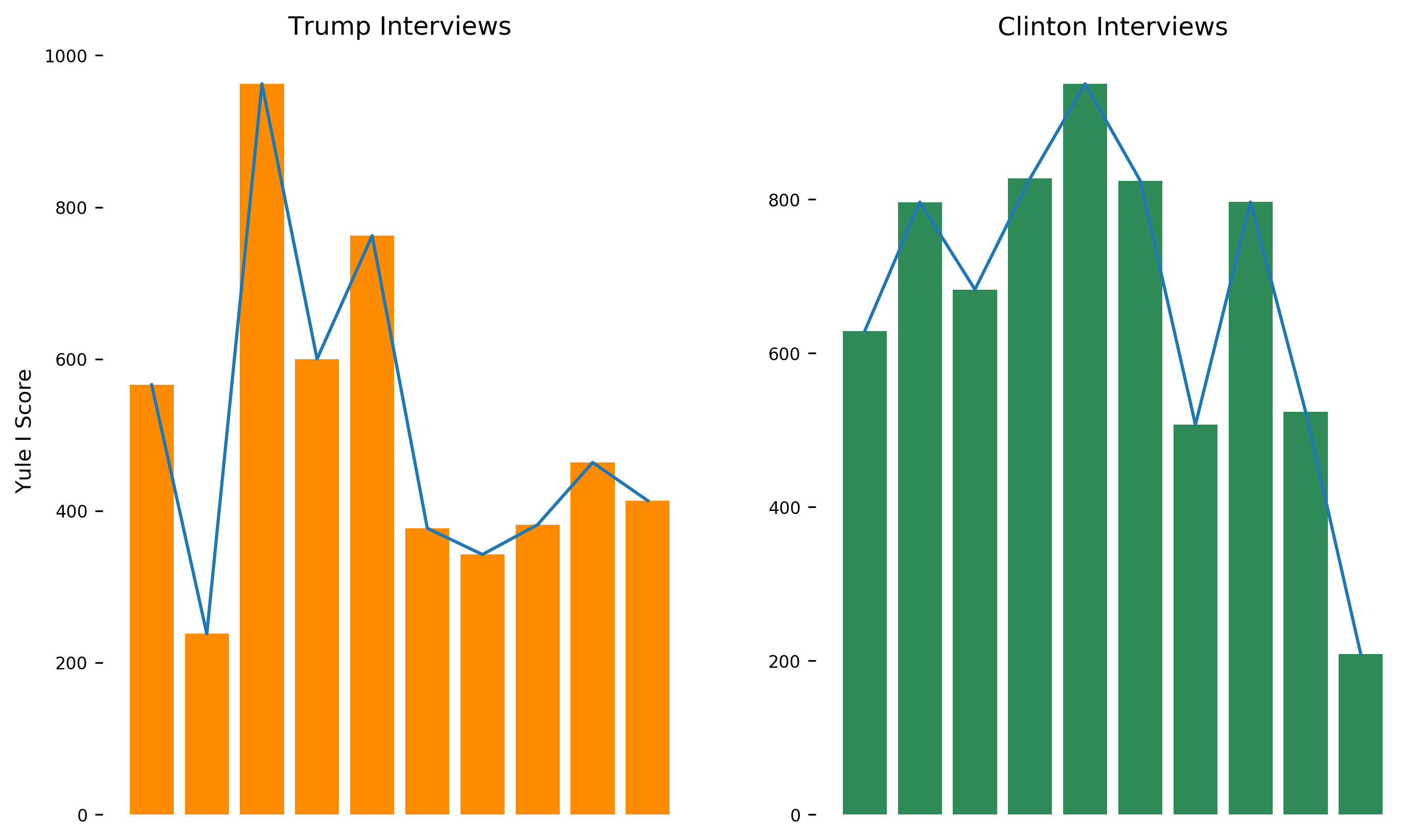
The Y-axis is decieving! Here’s some numbers to help with parsing the graphs:
| GWB | Trump | Obama | |
|---|---|---|---|
| Average | 727 | 510 | 657 |
| Median | 726 | 438 | 679 |
The mean and median are close enough, so it looks like the data wasn’t as contaminated as previously thought.
Collocations
While not exactly a metric, you can glean a lot from the collocations in a corpus; which gives us expressions of multiple words that occur together unusually often. These are often context-dependent, so there’s not a lot to be gained by comparing presidents.
Trump’s Interview w/ Piers Morgan
united states; european union; islamic terror; radical islamic; stock market; long time; second amendment; boom boom; paris accord; social media; big story; know nothing; anywhere near; previous administration; prime minister; terrible deal; 350 billion; electoral college; british people;
Trump’s Interview w/ Joe Kernan
… kernen; united states; long time; trade deficit; republican party; tax cuts; stock market; daca problem; tax plan; take care; even starbucks; 100 percent; better deal; executive order; human beings; paul ryan; setting records; worst recovery; little bit; obama quarter
Trump’s Interview w/ Kilmeade
insurance companies; west virginia; tax reform; middle class; nobody knows; tax cuts; percent increase; health care; 480 percent; john mccain; three brackets; tax cut; phase one; care reform; since obamacare; getting tremendous; news media; virtually everybody; tremendous support; drug companies
“Boom Boom” is a personal favorite, with “since obamacare” at a close second place. I really wish I could find a transcript of a Teddy Roosevelt interview to do this to.
Degree of Redundancy
Another interesting metric is sentence similarity. How similar is sentence i to sentence i +1 ? I use WordNet to generate a synonym set for sentence i, which is compared against generated synonyms using nltk’s path_similarity function. The function returns a score denoting the similarity between two words, based on the shortest path that connects the senses in the taxonomy.
def sentence_similarity(sent1, sent2):
def penn_to_wn(tag):
if tag.startswith('N'):
return 'n'
if tag.startswith('V'):
return 'v'
if tag.startswith('J'):
return 'j'
if tag.startswith('A'):
return 'a'
return None
def tagged_to_synset(word, tag):
wn_tag = penn_to_wn(tag)
if wn_tag is None:
return None
try:
return wn.synsets(word, wn_tag)[0]
except:
return None
sent1 = nltk.pos_tag(nltk.word_tokenize(sent1))
sent2 = nltk.pos_tag(nltk.word_tokenize(sent2))
synsets1 = [tagged_to_synset(*tagged_words) for tagged_words in sent1]
synsets2 = [tagged_to_synset(*tagged_words) for tagged_words in sent2]
synsets1 = [ss for ss in synsets1 if ss]
synsets2 = [ss for ss in synsets2 if ss]
score, count = 0.0, 0
for synset in synsets1:
best_score = 0
scores = []
for ss in synsets2:
sc = synset.path_similarity(ss)
if sc is not None:
scores.append(sc)
try:
best_score = max(scores)
except:
pass
if best_score is not None or len(best_score) != 0:
score += best_score
count += 1
# avg
if count != 0:
score /= count
return score
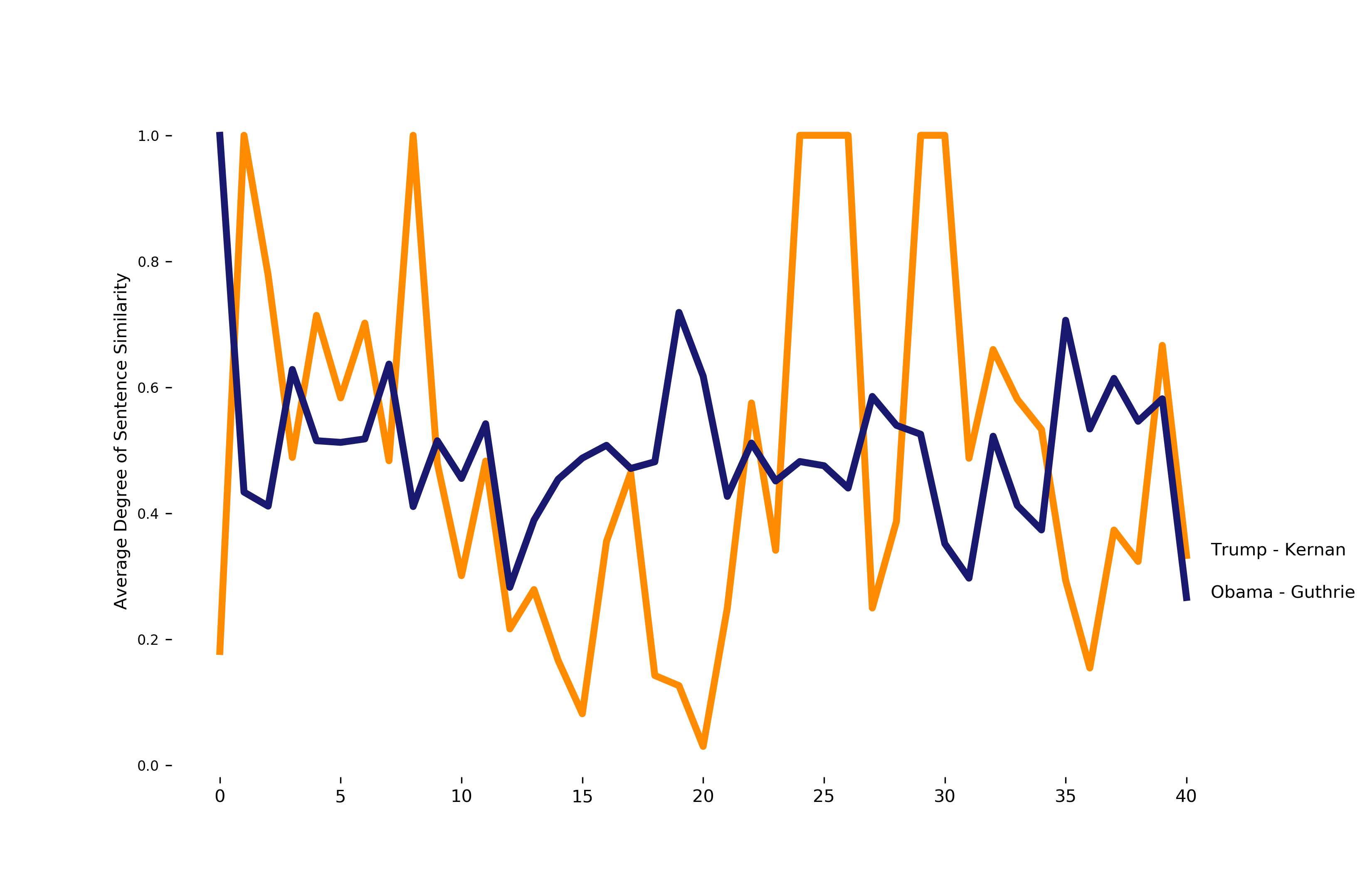
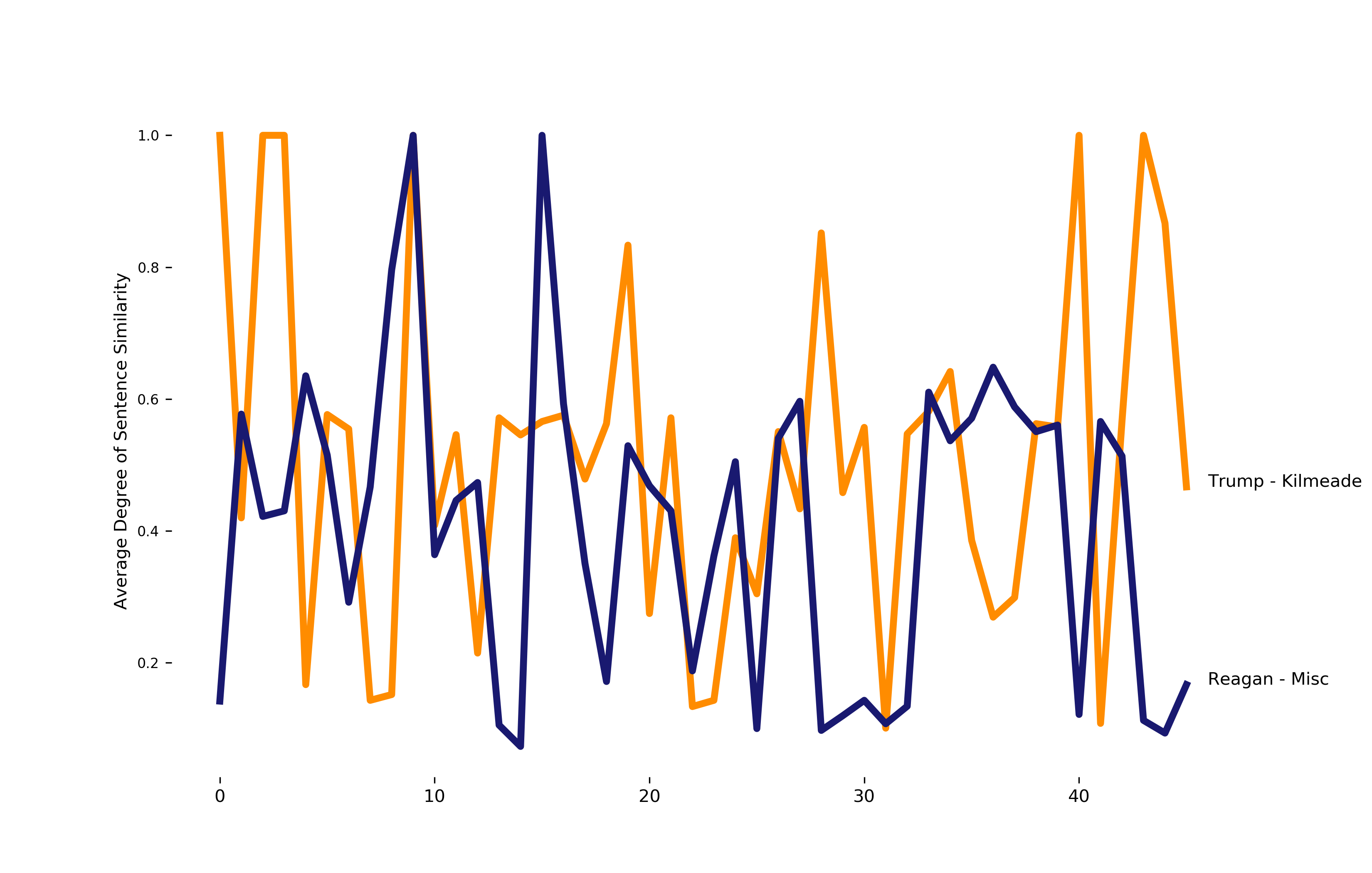
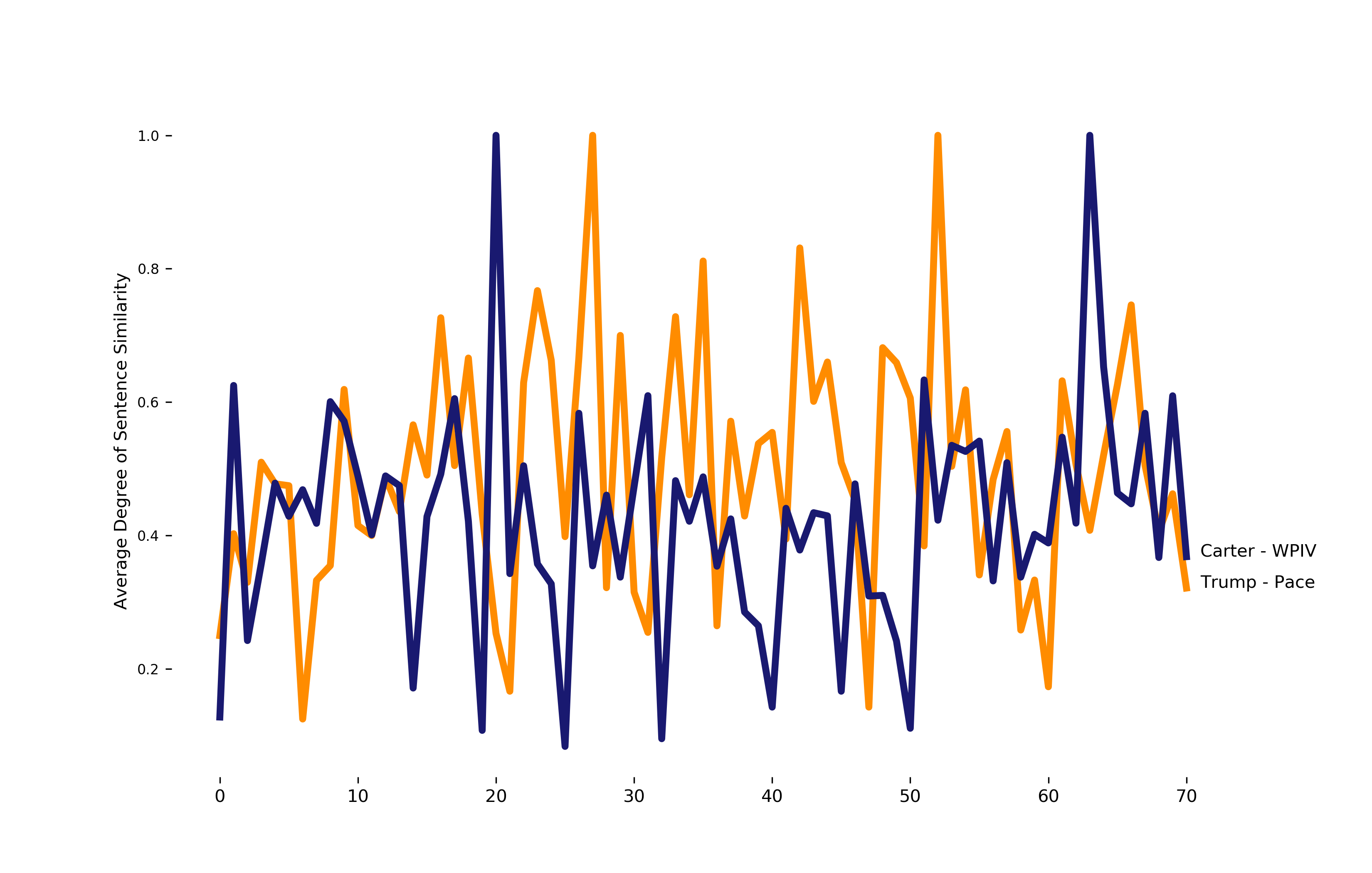
None of this is new to anyone that’s listened to Trump speak; he’s got a pretty unique way of saying things. However, it was a lot of fun applying basic computational linguistics techniques to try and visualize/put a number on what makes Trump’s speech distinctive.